

Data speelt onmisbare rol binnen Value-Based Healthcare
Het meten, vastleggen en analyseren van data zoals patiëntgegevens, proces- en financiële gegevens, speelt een cruciale rol bij Value-Based Healthcare. Denk bijvoorbeeld aan het meten van de effecten van een behandeling en het meten van de gemaakte kosten, zowel door het ziekenhuis als de patiënt. En zeker ook bij het vergelijken van de effectiviteit van verschillende behandelmethoden. Maar als je de effectiviteit van behandelmethoden wilt vergelijken, moeten de gegevens van andere artsen en zorginstellingen wel beschikbaar en te vergelijken zijn. Onmisbaar is dan ook dat diverse spelers in de zorg, in het bijzonder artsen, hieraan meewerken en zich conformeren aan erkende standaarden, denk aan ICHOM.
Aangezien het delen van gegevens zelfs binnen de muren van een ziekenhuis al niet overal vanzelfsprekend is, is hier nog wel een weg te gaan. Ik roep op om geen excuses te zoeken rondom privacy en professionele autonomie. Waar de wil is om mee te doen en van elkaar te leren, is de weg van privacy-borging echt wel te vinden. Zeker wanneer dit juist in het belang is van de patiënt(en). En maximaal gebruik van harde data zou vast onderdeel van de professionaliteit moeten zijn.
Veel van de benodigde gegevens voor VBHC vallen echter niet onder de noemer ‘Big Data’. Hebben we Big Data wel nodig in VBHC? Laten we eerst verkennen wat Big Data is en wat we ervan mogen verwachten.
Big Data vult reguliere medische gegevens aan
De verwachtingen rond Big Data zijn hoog gespannen en het gebruik hiervan wordt momenteel in allerlei toepassingen genoemd. Kan Big Data ook een extra impuls geven aan VBHC? Laten we eerst scherp krijgen hoe Big Data zich verhoudt tot reguliere medische gegevens. Onderstaande tabel geeft enkele kenmerkende verschillen:
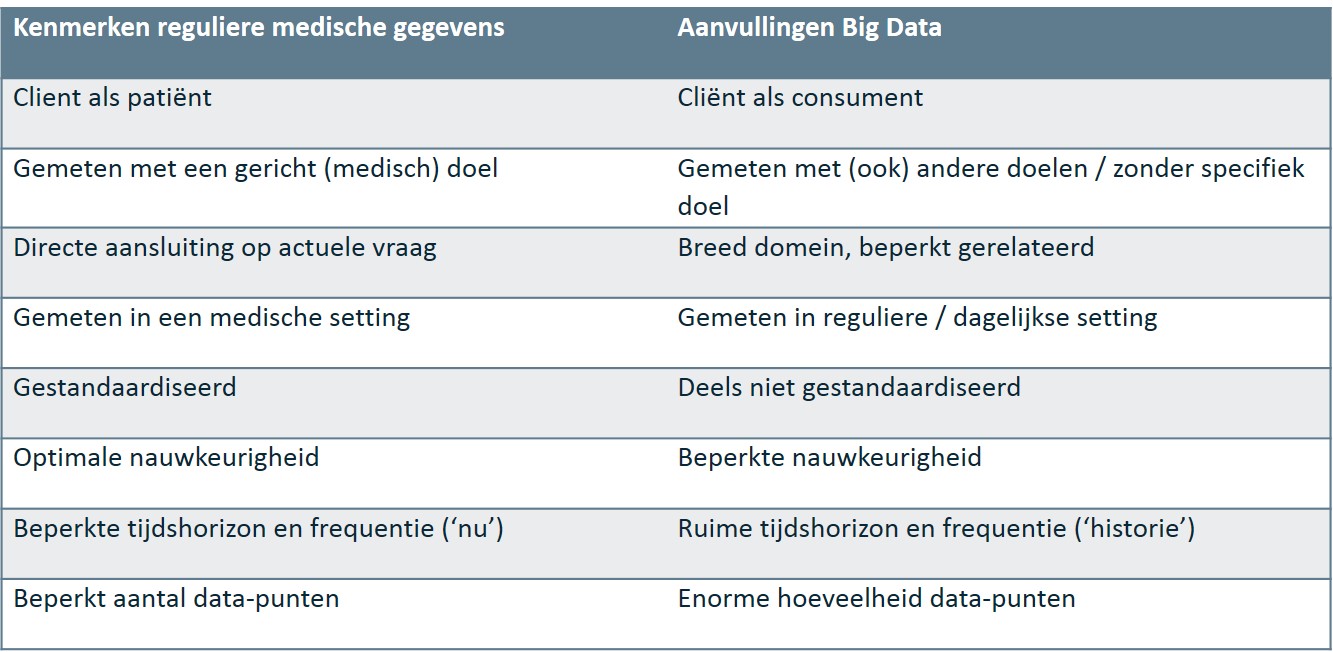
Belangrijk verschil is dat Big Data gegevens omvat die niet per se voor de betreffende diagnose of behandeling zijn gemeten, maar oorspronkelijk met een ander doel. Denk bijvoorbeeld aan de bewegingsgegevens van een fitness-app of het koopgedrag op basis van de app van een supermarkt. Aan de ene kant geeft dat een verrijking: andere meet-aspecten in een andere context. Aan de andere kant betekent dat vaak wel dat er enkele bewerkingen nodig zijn voordat de gegevens bruikbaar zijn. Voor een medicus betekent Big Data in de regel een teleurstelling in termen van ‘precisie’, maar het kan veel (indicatieve) inzichten opleveren op een breed domein en voor tijdperioden waar geen medische gegevens van beschikbaar zijn. Daarmee zal in de dagelijkse praktijk Big Data eerder voor hypothese-generatie waarde hebben, dan voor bevestiging van een diagnose.
Big Data gaat Value-Based Healthcare completer maken
Wat is nu de toegevoegde waarde van Big Data in het medische domein en voor VBHC? Ons inziens ligt die op korte termijn vooral in de meta-evaluaties over verschillende patiënten heen: welke behandelingen zijn in welke situatie het meest effectief? En in mindere mate: wat veroorzaakt de kostenverschillen tussen de behandelingen van verschillende ziekenhuizen? Hoewel we voor dat laatste met traditionele data-analyses bij goede data-kwaliteit al een heel eind komen.
Vooral het evalueren van behandelplannen, rekening houdend met een veelheid van persoonlijke patiëntkenmerken, gaat het beste wanneer dit op grote (wereld-)schaal gebeurt. Dit vanwege de grote data-volumes en ook omdat ongestructureerde data meegenomen wordt zoals afbeeldingen, social-media gegevens en bewegingsdata. Hier heeft Big Data duidelijk toegevoegde waarde.
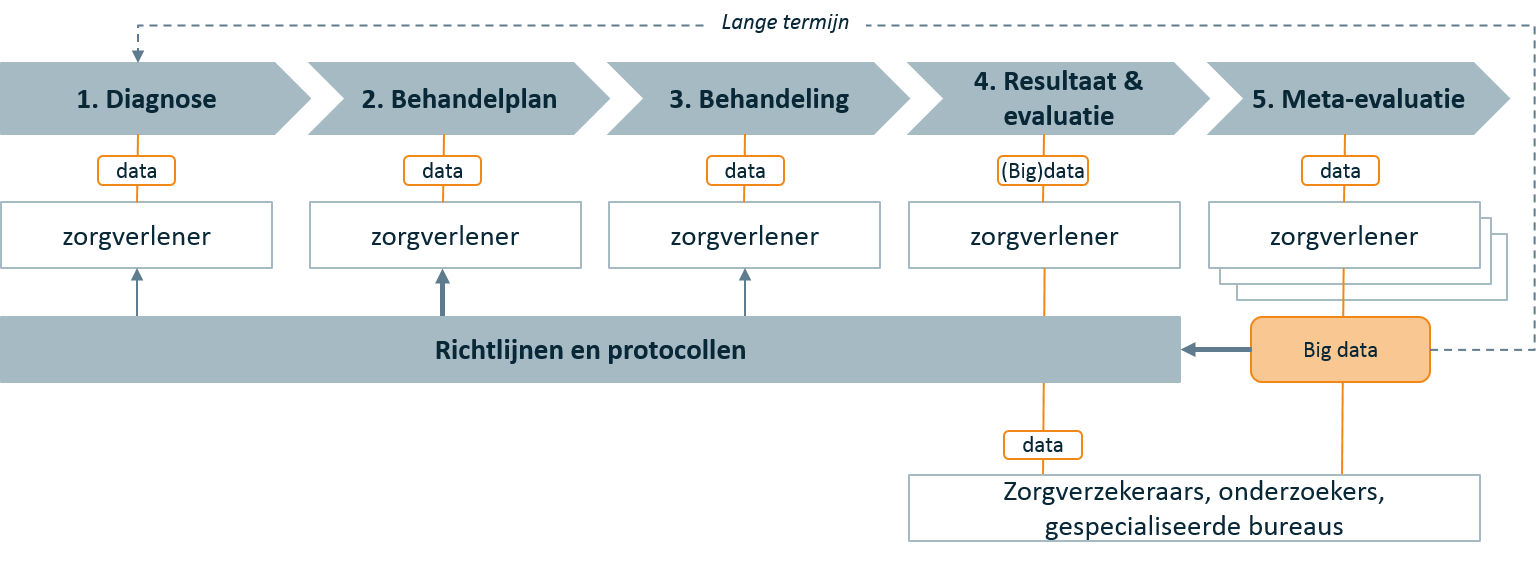
De toegevoegde waarde van Big Data in een VBHC-benadering
Als je kijkt naar het zorgpad dat een patiënt doorloopt (figuur 1), zie je de toegevoegde waarde van Big Data in een VBHC-benadering bij het evalueren van de behandeling van een individuele patiënt (stap 4). VBHC vraagt immers in de beoordeling van het resultaat ook om gegevens die meer te maken hebben met de patiënt als ‘consument’. Bijvoorbeeld: om te beoordelen of een patiënt weer hetzelfde kan functioneren als voorheen, bieden de gegevens uit de bewegingssensor van de mobiele telefoon een prachtige indicatie. Op iets langere termijn denken we dat Big Data ook van toegevoegde waarde kan zijn bij de eerste stappen van het zorgpad (diagnose en behandelplan). Met behulp van kunstmatige intelligentie kan de perfecte match tussen waargenomen patiëntgegevens, ziektebeelden en behandelplannen gemaakt worden, beter dan een dokter ooit zou kunnen, gegeven de bescheiden verwerkingscapaciteit van het menselijk brein ten opzichte van de computer. Voorlopig biedt Big Data waarde als second opinion of als check, maar in steeds meer gevallen als primair diagnosemiddel, met de arts als second opinion. Zo claimde IBM recent met Watson (ii) bij een 60-jarige dame een Leukemie diagnose in 10 minuten te hebben gedaan, waar artsen de voorliggende drie maanden niet uit waren gekomen.
Voor wie wordt Big Data dan onderdeel van zijn standaard gereedschapskist?
Niet iedereen hoeft Big Data te analyseren, wel zou iedereen data moeten delen en inzichten benutten. Voor wie wordt Big Data dan onderdeel van zijn standaard gereedschapskist? Wij denken allereerst aan gespecialiseerde onderzoekers en zorgverzekeraars. Ook ontstaat er ruimte voor nieuwe spelers, die vanuit een volstrekt onafhankelijke positie data verzamelen en analyseren.
Onderzoekers kunnen Big Data gaan gebruiken om evaluaties te doen en om standaarden en algoritmes te ontwikkelen voor diagnoses en behandelplannen. Zorgverzekeraars kunnen Big Data gebruiken om de prestaties van verschillende zorgaanbieders zorgvuldig te evalueren en hen van feedback te voorzien. Bij verzekeraars zien we het gebruik van Big Data al in hoog tempo op gang komen. De Amerikaanse verzekeraar Aetna sluit met zorgaanbieders al zogenaamde ‘pay for performance’ contracten af en biedt daarbij de benodigde tooling en data analyse diensten om de eigen prestaties te analyseren en evalueren. En in Nederland bijvoorbeeld is Achmea al jaren geleden begonnen in haar programma ‘Kwaliteit van Zorg’ met het transparant maken van uitkomsten, kwaliteit van leven en kosten.
Zorgaanbieders hoeven in de regel zelf geen geavanceerde analyses met Big Data uit te voeren. Maar ze kunnen wel de resultaten hiervan gebruiken. Met interne data en eenvoudigere analyses kunnen ze hun eigen functioneren meten, evalueren en verbeteren, geholpen door kant-en-klare software en apps. Big Data analyse, met bijbehorende statistische technieken, hoeft daarom ons inziens nog geen uitgebreide plaats te krijgen in het standaard curriculum geneeskunde. Zorgverleners moeten wel de bereidheid en vaardigheid hebben om zichzelf te laten leiden en corrigeren door data-gedreven analyses die hen worden aangereikt. En ze moeten de patiënt vervolgens kunnen informeren over de te verwachten effecten van verschillende behandelingen in zijn specifieke situatie, inclusief de mate van onzekerheid hierover, zodat de patiënt zelf kan bepalen wat het beste aansluit op zijn wensen.
Hoe nu verder
Om de genoemde voordelen van Big Data voor VBHC te kunnen realiseren en benutten, is het nodig om informatie te delen, te conformeren aan standaarden en open te staan voor feedback en nieuwe inzichten. De Big Data details mogen voor veel zorgverleners een black box blijven, als er maar de bereidheid is om de verkregen inzichten uit Big Data toe te passen in de praktijk en andersom ook gegevens te delen voor het collectieve geweten. Dan komt er vaart in VBHC en kunnen patiënten meer kwaliteit van (dagelijks) leven tegemoet zien.
i
Big Data is niet scherp gedefinieerd, maar voor deze blog is het voldoende om het te duiden als het gebruiken en analyseren van data met als bijzondere kenmerken:
- Grote hoeveelheden
- Deels ongestructureerd (bij gestructureerde data heeft elk data-veld vast gedefinieerde kenmerken, bij ongestructureerde data weet je zelfs niet op voorhand waar de data over gaat en waar in je database de gegevens staan die je zoekt)
- Eventueel hoge snelheid van genereren en verwerken.
ii
Watson is een supercomputer die ontwikkeld is door het Amerikaanse bedrijf IBM en gebruik maakt van kunstmatige intelligentie. Hij kan een in spreektaal gestelde vraag interpreteren en na een zoektocht door een verzameling van encyclopedieën, boeken, tijdschriften, wetenschappelijke artikelen en gedownloade websites binnen enkele seconden een goed antwoord op de vraag geven.




